この記事は論文翻訳ではありません
2022年の夏にProtocol Labs Researchから出ていた,Kademliaの最適化に関するカンファレンスペーパーを読んだのでまとめていく.
問題意識
従来のKademlia,もしくはIPFSで使われているKademliaでは論理アドレスにおける距離と物理的な距離に一切の相関はない.これはIPアドレスなどのハッシュ値を論理アドレスとするので実質ランダムな値になるためである.ある程度ローカライズされたネットワークを前提とすれば問題はないが,これが例えば世界規模のネットワークだった時に,ブラジルのノードと日本のノードが論理アドレス上だと隣り合わせになる,みたいなことが起きうる.レプリケーションという意味で言えば一つのk-bucketに世界中に散らばったノードがあるのは良いことだが,リフレッシュ処理やRepublicationの際に毎度毎度RPCを日本-ブラジル間でやりとりするのが非常に非効率なので,論理アドレスの距離と物理的な距離をある程度マッチさせようというのがこの論文の目的である.
既出の解決策としては,Coralのように各ノードのレイテンシーを情報として保存することで高速なノードを優先的に用いてルーティングを行う方法や,GeoPeer,NL-DHTやGeodemliaのように,既に存在する座標システム(GPSや直交座標系など)を論理アドレスに直接適用する方法が挙げられる.前者に関しては,各ノードのレイテンシーを計測する段階でネットワークを圧迫してしまうことと,そもそもレイテンシー自体が動的なもので頻繁な再計測が必要になることから改善の余地がある.後者はこの論文の主旨と近いところはあるが,一つの物理座標システムに縛っており,かつ論理アドレスのネーミングのみならず検索アルゴリズムなどにも手を加えているというデメリットが存在する.
上記の既出技術を踏まえて,この論文では,座標システム非依存かつ決定的(頻繁な再計測や再計算を要しない)な最適化方法を二つ提案している.
解決策
1. Soft Partitioning
Soft Partitioningは至ってシンプルで,通常通りに生成された論理アドレスの前にLocalityごとに定められたPrefixを付加する,ただこれだけである.この方法では,論理アドレスのルール以外は一切変えずにLocality-basedなルーティングを実現する(だから"Soft" Partitioning).それでいてXORを取った際の距離はPrefixが同じであれば近くなり,違えば遠くなるためPartitioningは成功している.
// 例(ハイフンはPrefixとハッシュ値の区別のため)
locality1-afe04579004049ccce1843a40bdf9eb85f3a4839390375e35d0018a7f9aa70c8
locality2-105618902890e672d88e66a78e2590a554f9b5b004ed154a4b489b2c6819b393
コンテンツの論理アドレスに関しては,元の発行者のPrefixと同じものを付加する.よくアクセスされるコンテンツであればどのみち他のPartitionにもコピーされるため大きな問題はない.
2. Hard Partitioning
Hard Partitioningでは,Prefixなどではなく,Localityごとにネットワークを分割してしまうという方法である.Localityが違う場合,もう距離が遠いとかそういう次元ではなくそもそも距離が存在しないことになるので,別のPartition(=別のネットワーク)にあるノードにアクセスする場合はIndexer Serviceと呼ばれる仲介サーバーを用いる.Indexer Serviceは他のPartitionそれぞれについていくつかのノードの情報を持っており,RPCをそのまま該当する別のPartitionに転送するようなリレーサーバー的な役割を持つ.Indexer Serviceへの負荷集中を避けるため,各ノードは頻繁にアクセスするノード情報をキャッシュとして持っておく.
この後の検証の際に使われるIndexer Serviceは外部の中央集権的サーバーであるが,スーパーノードのように,いくつかの安定したノードに他Partitionのノードの情報を持たせてIndexer Serviceの役割を担ってもらうことも論理的には可能である.
検証
検証パートでは正常なネットワーク(Fault-free Network)と30%の通信が失敗するネットワーク(Faulty Network)に環境を分けて検証を行っている.
Fault-free Network
Fault-free Networkでは,FIND_NODEとFIND_VALUE両方のオペレーションについて,Partition数3/10/100個でレイテンシーを計測した.
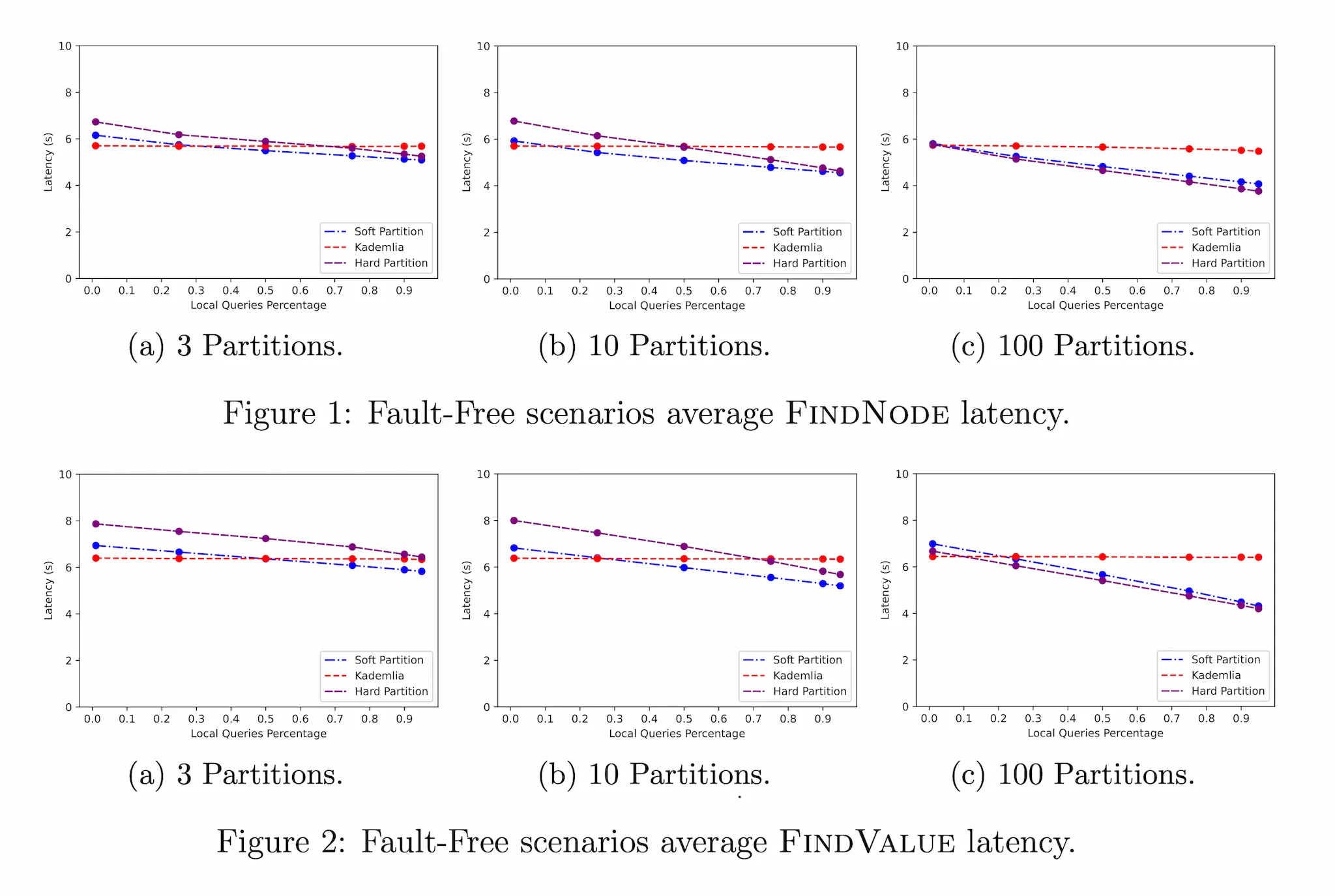
どちらのオペレーションのどのPartition数においても,クエリー数が増えるとオリジナルのKademliaアルゴリズムのレイテンシーが他より大きくなっている.さらにPartition数が増えれば増えるほどSoft PartitioningもHard Partitioningもレイテンシーが減っていることが分かる.Hard Partitoningは一つのPartitionのノード数が少ない(Partition数が多い)ほどそのネットワーク内のルーティングは高速になるためSoft Partitioningよりも高速になるが,Partition数が少ないとIndexer Serviceに集まるクエリーの数が多いためボトルネックになる.結果としてSoft PartitioningとHard Partitioningはさほど変わらないレイテンシーに落ち着いている.
FIND_VALUEはFIND_NODEと同じ手順に加えてコンテンツを取得する手順が加わるため全体的にFIND_NODEよりレイテンシーが大きくなっている.
Faulty Network
Faulty Networkにおいては,FIND_NODEについてPartition数10/100個でオペレーションの成功率を計測した.120秒間Fault-freeな状態で動かしたのちに意図的に30%の通信を失敗させている.
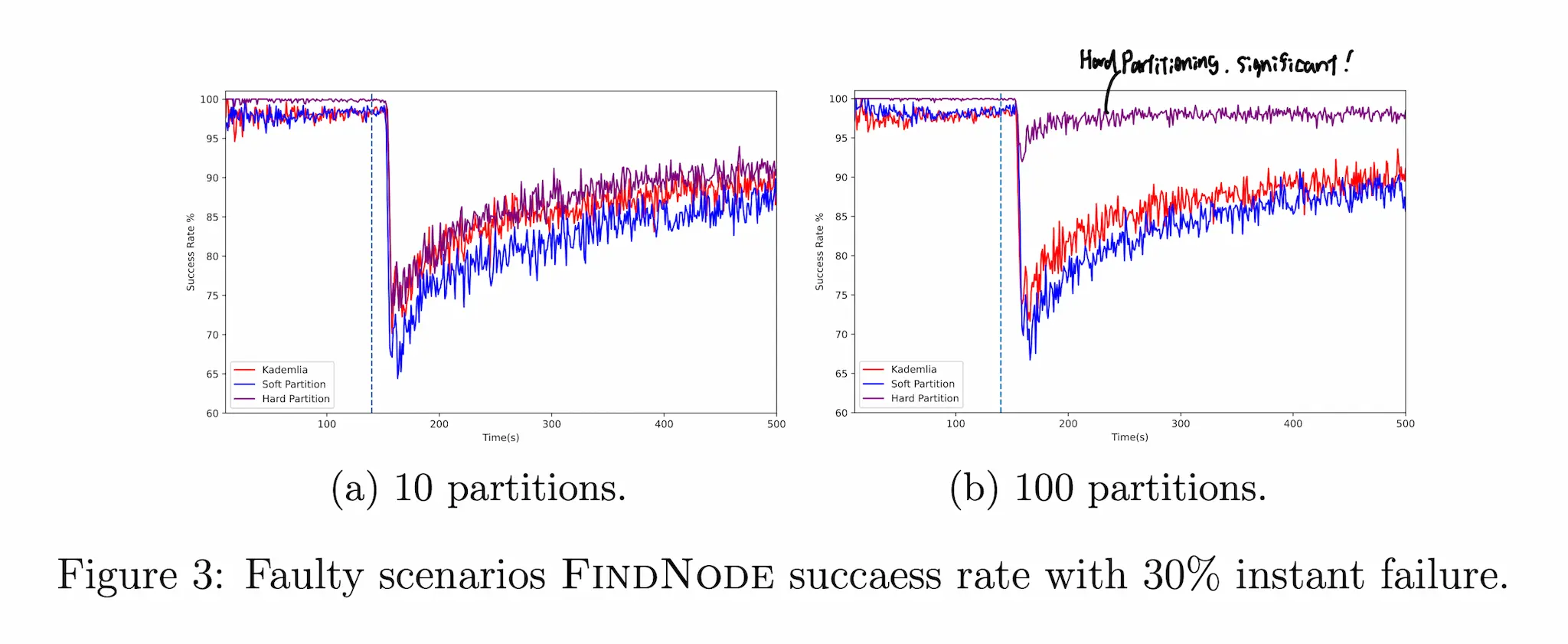
この状況下だとSoft Partitioningが最も効率が悪いことが分かる.さらに特徴的なのは,Partition数100個の際,Hard Partitioningのオペレーション成功率が以上に高いことである.これは分割されたネットワークの数が多く,あるノードにアクセスする際に回り道がたくさんあるためである.ノードだけでなく,その上の階層のDHTでまたネットワークが形成されていると考えると分かりやすいかもしれない.
おわりに
Hard Partitioningの障害耐性がすごいというのは勿論そうなのだが,結局外部サーバーを使ってしまったらP2Pネットワークの良さが大幅に減ってしまうのでこれがすぐにIPFSに実装されるとか,他のP2Pネットワークで実装されるというようなことはない気がする.とはいえ一つの座標システムなどに限定しない柔らかさは普及に貢献しそうなのでlibp2pチームがこれをどう改善して実装まで持ってくるのかが楽しみである.


